Explain to Me: Why Train A Model Generatively and Discriminatively
Summary
These are my thoughts on why we want to train a model generatively and discriminatively (or why we want to train a model using unsupervised fashion and then supervised fashion):
- We want to make use of unlabeled data to optimize the model. Sometimes getting labeled data is much more expensive. e.g. object recognition.
- An optimal model may not exist when trained purely generatively or purely discriminatively, but in the middle.
- From a deep architecture perspective, the input features is in general much higher dimensions than the output classes (usually just an integer or even boolean). As such, the error signal generated by the output classes on getting wrong is smaller than generated by the input features. Deep architectures have a tendency to overfit easily (read: get stuck in local minima), and a weak error signal can easily trick the learning algorithm to fall into local minimas.
Point 1 is straightforward. Point 3 warrants another long post. Below, I will explain a little insight about point 2.
Distinguishing Mushrooms as a Human
Suppose you are trying to distinguish between mushroom types with naked eye, even without a teacher, you can easily distinguish most mushrooms because many of them are quite different.
For instance, it is not hard to tell between the coprinus comatus and jack-o-lantern below. One is white and one is orange, and their shapes are very different.

However, the jack-o-lantern and chanterelle will be harder. Both are orange and have similar shapes.

You might be tricked to think they are the same or just slightly different, but they are very different: The jack-o-lantern is a poisonous mushroom!
Notice that you as a human can easily distinguish betwen many mushrooms, but you will get it wrong more often when very similar types of mushrooms are put together. However, if a teacher is there to tell you the two mushrooms (jack-o-lantern and chanterelle) is indeed different mushroom types, naturally you will look harder for the features that distinguish these two very similar types because now that you know they are different!
Why Train A Model Generatively and Discriminatively
Generatively trained models try to model the joint distribution between the input features and the output class, but the assumed model may not match the real model that actually generated the data, and this causes the discriminatively trained models to perform better in practice (see earlier post for more detailed explanations).
Like the example above, if a generatively trained model can be later trained discriminatively (i.e. taught by a teacher to correct mistakes), then:
- It will have the advantages of learning generatively, which unlabeled data is much easier to obtain and works better than discriminative models theoretically.
- The wrong generative assumptions can be compensated by learning discriminatively.
Experiments
Christopher Bishop wrote a very good paper on training generatively and discriminatively. Below is the results of using different mixtures of the generative model and discriminative model to perform object recognition.
Specs of the experiment:
- Object recognition, a classification problem.
- Model will predict 8 classes in total.
- Training data: 400 images total. 50 images per class. Out of each batch of 50 images, only 5 are labeled, the other 45 are unlabeled.
- Testing data: 800 images total. 100 images per class.
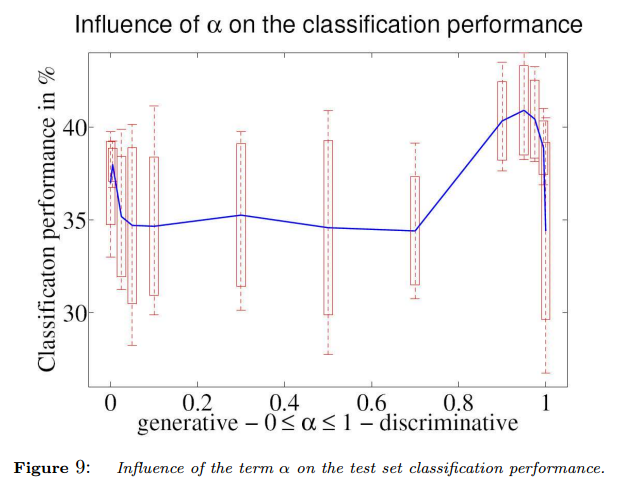
The best performance is seen when alpha is about 0.95 (slightly generative mostly discriminative), which illustrates point 2 in my summary above.
I hope this builds more intuition into why we want to train a model with a mix of generative and discriminative fashion.
References: