Tea time with: Galaxy Zoo: Reproducing Galaxy Morphologies via Machine Learning
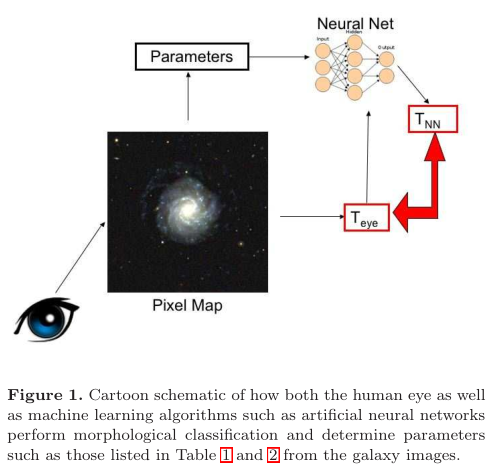
Goals
Galaxies are vast and many. This paper explores if a machine learning approach to this problem can perform on par or even better than human classifications.
Notes
- Galaxies are classified into different categories based on their observed characteristics like shape, color, etc. The SDSS DR6 is a system of classification, which humans manually classified galaxies into 3 classes : 1) early types, 2) spirals, and 3) point sources/artifacts. Classifications are made by asking a series of questions structured as decision trees. Note that since most photos of the galaxy are not of high quality, ambiguous and even contradicting answers can occur. Input label quality varies widely.
- The authors assert that machine learning performance depends crucially on the human classification of the galaxies (garbage-in-garbage-out), which is understandable for the reason of varying label quality.
- A neural network with two hidden layers is used in this case. The output layer is just 3 nodes, representing the confidence it is in a 1) early types 2) spirals 3) point source/artifacts.
Findings
- With good enough features (1) colors and traditional profile-fitting, a total of 7 features, and 2) adaptive moments, a total of 5 features), machine learning performs very well on different subsets of the entire sample. However, using only the feature set of 1) colors and traditional profile-fitting or 2) adaptive moments alone yields poorer results. Traditionally in old papers, only 1) is used.
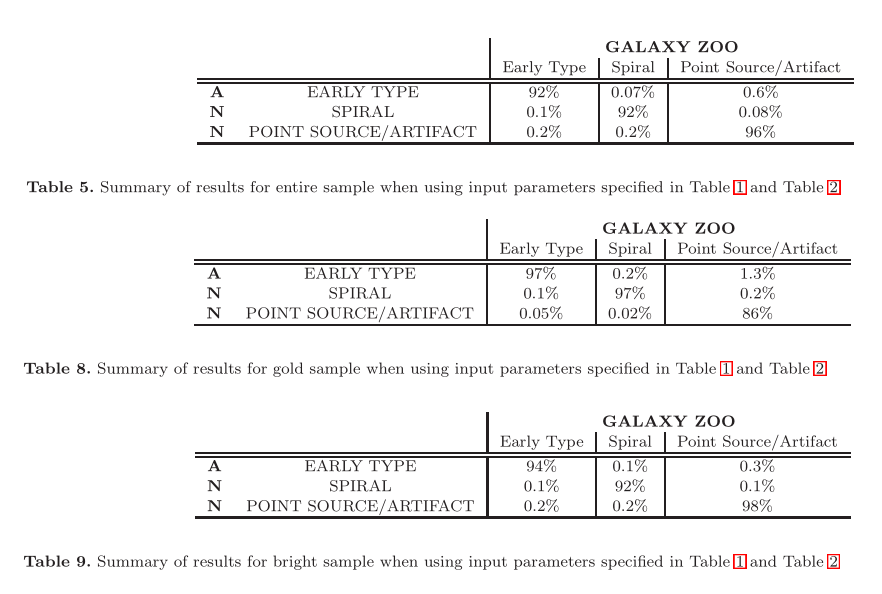
- The “gold sample” is the set of photos with a label that has greater than 0.8 in any of the categories. Machine learning model perform very well on these models with 86~97% accuracy. The data size is about 315K.
- The “entire sample” is everything. Machine learning models perform well only if the full set of features 1) 2) is used, it performs very bad on using just 2), as there are two classes (the early types and spirals) are very similar just from these features. Data size is about 800K.
- A “bright sample” is a collection of galaxy photos with the more distant faint images filtered out. Apparently the brightness of the galaxy has a significant effect as well to the machine learning performance as well. Data size is about 340K.
Results
I’ll capture the tables from the paper itself, which is very clear. Table 5, 8, 9 are the results of using all features for the entire sample, gold sample, and bright sample respectively.
The paper is available here.