Tea Time With: Convolutional Deep Belief Networks for Scalable Unsupervised Learning of Hierarchical Representations
Goals
The deep learning algorithms at that time do not scale to high dimensional input. This paper tries to address this problem.
Key Points
Reasons why deep learning algorithms do not scale:
- At the time of the paper, Restricted Boltzmann Machine chokes at 30 x 30 pixels input, much lower than realistic requirements. Convolutional Deep Belief Network (CDBN) tries to scale this up to 200 x 200 pixels.
- RBM choke because the same feature detector learned at a location cannot be used on another location (i.e. not translation invariant).
How convoluted deep belief network works on a high level:
- Deep learning stresses on having every next layer learns a higher feature representation of the lower layer’s features. For example, think of recognizing digits as three parts: 1) Detect lines from raw pixels, 2) Detect corners, contours based on lines, 3) Detect unique digits features based on corners, contours.

- Introduces the Convolutional Deep Belief Network (CDBN), which is just stacking layers of Convolutional Restricted Boltzmann Machine (CRBM) over each other. Each CRBM acts as a feature detector. The stacking for a CRBM looks like below:
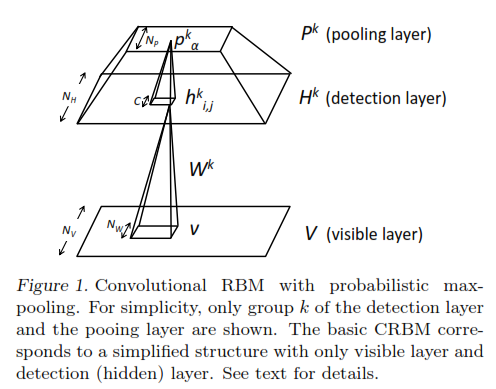
How does CDBN solves the scaling problem:
- A traditional Restricted Boltzmann Machine (RBM) has no pooling layer. The CRBM, which makes up the CDBN, has this extra pooling layer on top of hidden layer which shrinks the hidden layer details before feeding it to the next layer in the CDBN. Shrinking is to drop the details learnt by a factor or 2 or 3. This effectively drops some noises which allows small translations to happen, reducing computational burden as well.
- In DBNs, when a given feature is learnt (i.e. the weights are learnt), it is not shared across other locations of the image. This redundancy means extra computational work. CDBNs have weights that are shared among all locations in an image.
Findings
 Above is the features learnt by the CDBN visualized. The upper row is what the 2nd layer of the CDBN ‘sees’, and the lower row is what the 3rd layer of the CDBN ‘sees’. It is pretty close to what a human would expect as well.
Above is the features learnt by the CDBN visualized. The upper row is what the 2nd layer of the CDBN ‘sees’, and the lower row is what the 3rd layer of the CDBN ‘sees’. It is pretty close to what a human would expect as well.- One interesting result is that the CDBN trained on the Kyoto natural image dataset, when tested on the Caltect 101 dataset, yielded a result of ~65.4%, on par with state of the art. Meaning that the CDBN could have built some real good generalization, and not just the things it was trained to recognize.
The paper contains much more insight which readers are encouraged to read the paper and presentation.