Tea Time With: An Empirical Comparison of Supervised Learning Algorithms
Goals
Find out which learning algorithm is better or worse than the others in a systematic manner.
Paper can be downloaded here.
Key Points
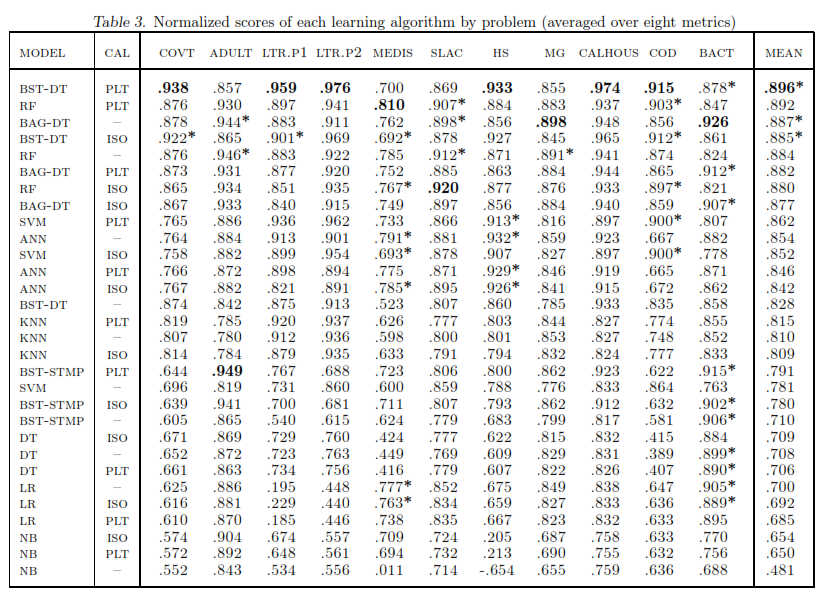
- The top models are: Boosted decision trees, random forests, bagged decision trees, SVM, neural networks.
- The worst models are: Naive Bayes, Logistic Regression, Decision Trees.
- Even the best model can perform poorly on some datasets. Note that the results present means the algorithm ranked top performs in general the best, albeit it performs poorly in some datasets.
- If a model selection is done by looking into the test set (data snooping), the final model performance increases, which is expected. However, models with the high variance increases the most (like ANN, SVM, but not boosted or bagged models, which decreases variance but increases bias), because validation sets does not always select the model with the best performance on the final test set.
- Platt Scaling and Isotonic Regression are techniques to scale a classification of a model to posterior probabilities (i.e. [0,1] scale).
About the Experiment
- Run multiple learning algorithms against 11 problems each with a 5-fold cross-validation for model selection.
- All learning algorithms: Support Vector Machines (SVMs), Artificial Neural Network (ANN), Logistic Regression (LOGREG), Naive Bayes (NB), K Nearest Neighbours (KNN), Random Forests (RF), Decision Trees (DT), Bagged Trees (BAG-DT), Boosted Trees (BST-DT), Boosted Stumps (BST-STMP).
- Training size is 5000, and the rest of the data is always testing set.
- A total of 8 metrics, including accuracy, area under ROC curve, etc.
- Scores are calibrated via Platt Scaling or Isotonic Regression for models that give binary output.