Improving Classifier Performance With Synthetic Features
When you train a classifier on a dataset, often that you are stuck at a certain performance and are unable to get past it. At this time, you may add new training data, use a more complex model, etc to boost the performance of the classifier. However, you may not always be able to add more training data, or may have a large dataset such that using a more complex model is infeasible computationally.
So, what can I do?
We can add synthetic features to the dataset, which is a form of feature engineering. You can view it as adding a higher level representation of the raw dataset.
For instance, if you have to predict whether it is feasible to drive between two pairs of latitude and longitude points. Let’s say feasible is that we are driving our car and we can’t drive for many days. Then, the dataset would look something like this:
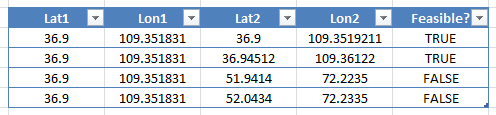
As you can see, the first two examples are feasible because they are rather close by, and we give it TRUE. However, the third and forth examples are clearly not feasible since they are too far away, so we give it a FALSE.
Now the distance is actually calculated via a very complicated formula called the Harversine Distance. A classifier may not be able to learn this complicated formula very well. (As always, if you have the mathematical formula, just use it, it gives you perfect answers, quickly. We use machine learning when we cannot pin the problem down mathematically.)
However, if we add a new synthetic feature which is to calculate the harversine distance and feed it to the classifier for training, the classifier can easily correlate this feature with the output. This acts as a higher level representation of the latitude and longitude points. The dataset now looks like this, with an extra column called “Distance” below:

Here is a dataset that I generated and trained via Logistic Regression. The results are as follows:
Best cross validation score without synthetic feature : 0.714285714286
Best cross validation score with synthetic feature : 1.0
Clearly, we can see a major boost to the classifier performance with the new synthetic feature.
But, but, how do we know what feature to engineer?!
Yup. I bet you are asking the question : how do I know what feature to add in my case? We know the Harversine for calculating distance between two pairs of points, but how about other general datasets? Unfortunately, to my knowledge, there is no clear science as to how you find out what features to engineer. There is also very little literature on this topic in a practical environment. I would love to write more about it when I have a more consolidated understanding.
So, are we doomed?
Not really, one way to do it is to find it out using bruteforce. I think this will be really slow and not really the craftsman way, but nevertheless seems to be a feasible approach. You may also look into previous literature on how they deal with the problem as well.
The general methodology is to try to construct new features via some operations on the initial features through all binary (or more) combinations. Perhaps you may for each pairwise feature (assuming real-valued) multiply them together, or sum them together, and append each result as a new synthetic feature. Yes, I know this sounds odd but then, use this unless you have no better solutions at the moment. Using the Vertebral dataset, here is what I got using Logistic Regression to train with different sets of synthetic features:
1) Run without any modifications to original dataset
Final best score : 0.854368932039
2) Construct a variable from every pair of two features via multiple / divide / add / subtract , use the feature one at
a time
Final best score : 0.870550161812
3) Construct two variables from every pair of three features via multiple / divide / add / subtract , use the feature two at a time
Final best score : 0.870550161812
4) Construct three variables from every pair of four features via multiple / divide / add / subtract , use the feature three at a time
Final best score : 0.870550161812
5) Construct n^2 features (n = number of features) for each pair of features via multiple / divide / add / subtract , and use the features all at the same time
Final best score : 0.844660194175
As you can see, on a training dataset without synthetic features, you have 0.854 performance, but with synthetic features, you can boost it up to 0.87055 performance, which is not too bad to have depending on your application. Of course, we do not really know why it boosted performance, but it just works.
Now that you see the power of adding synthetic features, a form of feature engineering, you may go improve your prediction rates!
You may find all the code here.